The first step in getting started with building a custom project for ReactiveSearch is to add your own data. In this guide, we explain how you can import your data with the correct schema.
Creating an App
ReactiveSearch uses Elasticsearch as its underlying database system. An app within ReactiveSearch's context refers to an index in Elasticsearch.
Here's a short gif walking through the app creation process in appbase.io, a hosted realtime Elasticsearch service.

If you are using an Elasticsearch cluster, you would be able to create an index with the following command:
curl -XPUT elasticsearch:9200/my_app/Note
ReactiveSearch is compatible with Elasticsearch v2, v5 and v6.
Overview of the App Data Model
Elasticsearch's data model is JSON based, and data within an app is organized as JSON objects that belong to a type (or not if you are using v6). Types provide a logical namespace to the JSON data which can be used while querying data. You can read more about the data model behind Elasticsearch over here.

Note
Elasticsearch v6 removes the concepts of types, where data is simply stored as JSON objects within an index.
Importing Custom Data
In this section, we will cover how to add data using three different approaches. We will use Dejavu - a GUI for Elasticsearch for showing the process.
via Importer
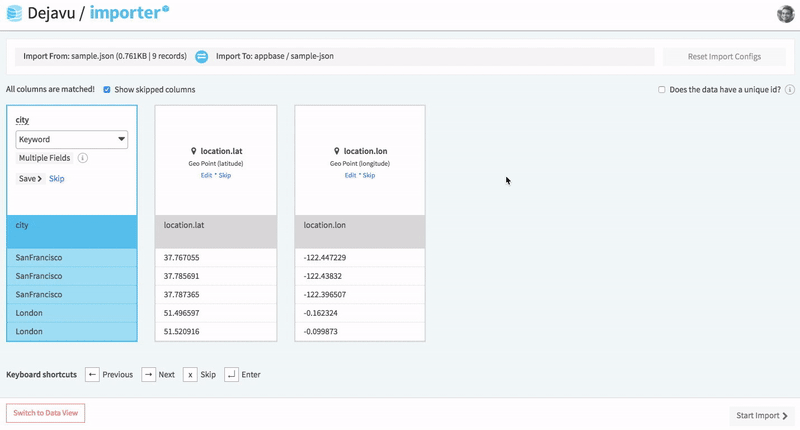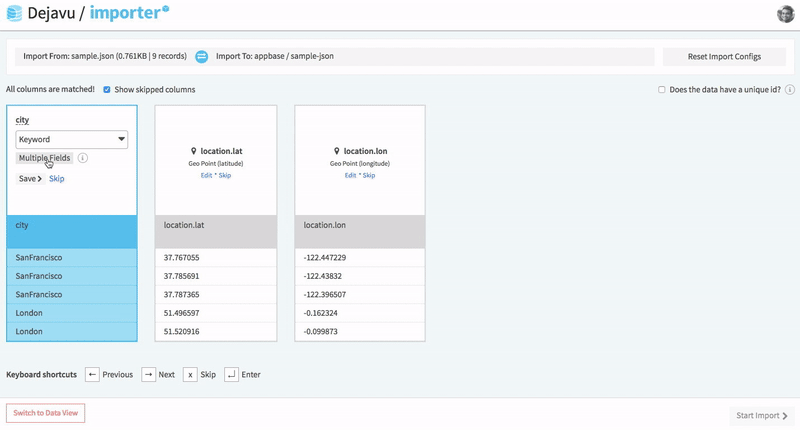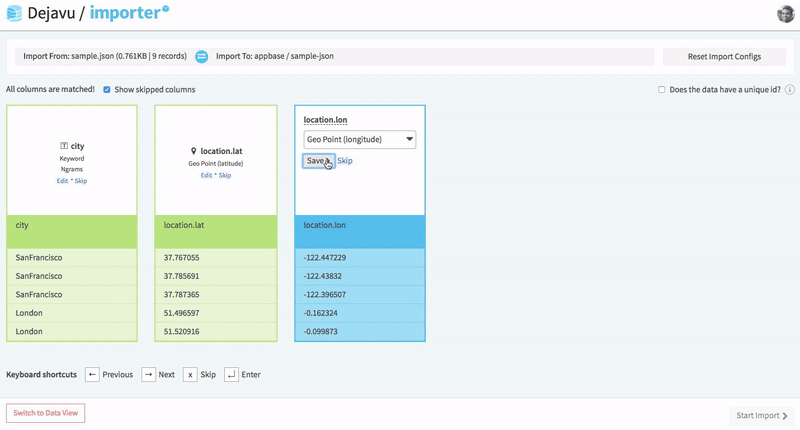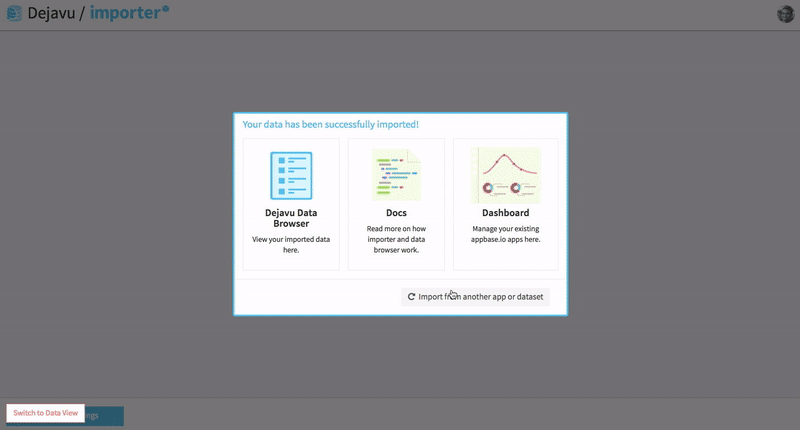
Importer is the most recommended way to index data into an Elasticsearch index. It works with JSON and CSV file types, and also supports cloning an existing app.
Importer also allows you to configure mappings prior to indexing the data.
via Dejavu GUI
Let's say you have your data organized as a CSV or XLS file.
- Use an online tool like http://www.csvjson.com/csv2json to convert your CSV data into a JSON format.
- Go to your dejavu's Data Browser section and click "Add Data".

- Add the JSON formatted data here, a single object should be added as a JSON object while multiple records can be added using the Array semantics.
Tip
Add up to a hundred records at a time for best results. Ideal when your data set is small.
via API
Elasticsearch uses a RESTful API for both indexing and retrieving data. Whether you are using Python or Java or Javascript, you make a HTTP API call there.
This is how a REST call looks to insert a single object into an app inside a type called books.
curl -XPUT https://[email protected]/$app/books/1 --data-binary '{
"department_name": "Books",
"department_id": 1,
"name": "A Sample Book on Network Routing",
"price": 5595
}'scalr.api.appbase.io is the domain for the Elasticsearch cluster, you can replace this with the location of your cluster domain.
Data Mapping
Data mapping is the process of specifying a schema for your data, which determines how fields are indexed and stored. While Elasticsearch auto-detects the schema based on the kind of JSON value through a process known as dynamic mapping, it is also possible to set this mapping statically. You can read more about mappings over here.
Dejavu provides a GUI for setting the mapping of a new field, as well as viewing existing mappings.
Note
If you are coming from a SQL background, there are two things to keep in mind regarding Elasticsearch mappings:
- They are immutable. Once specified (or dynamically set), they can't be changed.
- Being a full-text search engine as well as an aggregations engine, Elasticsearch supports specifying multiple mappings for a field. This allows it to store the same field in different ways, thus allowing for versatile querying.
Custom Analyzers
We recommend adding the following custom analyzers to your Elasticsearch index. We will use them when specifying mappings for a $dataField to be used for searching.
The autosuggest_analyzer indexes the field by breaking each word into tokens of length [1, 20] always beginning with the first character of the word. This allows for fast suggestions retrieval in a DataSearch UI.
Note
If you are using dejavu/importer for indexing data, it already supports these custom analyzers with the
TextandSearchableTextdatatypes.
Adding custom analyzers requires you to first close the index with the following command:
POST /:index/_closefollowed by the actual addition of analyzers with:
PUT /:index/_settings
{
"analysis" : {
"analyzer":{
"autosuggest_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"autosuggest_filter"
],
"tokenizer": "standard",
"type": "custom"
},
"ngram_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"ngram_filter"
],
"tokenizer": "standard",
"type": "custom"
}
},
"filter": {
"autosuggest_filter": {
"max_gram": "20",
"min_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol"
],
"type": "edge_ngram"
},
"ngram_filter": {
"max_gram": "9",
"min_gram": "2",
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol"
],
"type": "ngram"
}
}
}
}followed by opening of the index. It is important to open the index up for any indexing and search operations to occur.
POST /:index/_openYou can read more about this over here.
Text Datatype in Search v/s Aggregations
There are two different types of use-cases that Elasticsearch supports:
- Search - We talked about this use-case in the above section. Here, we typically apply a search specific analyzer to get fast and accurate search results back. The field to be applied in the
dataFieldprop for search specific components is ofTexttype (v5 and above) or ofStringanalyzed type (v2). - Aggregations - Aggregations and sorting are operations that require using a non-analyzed string. The field to be applied in the
dataFieldprop for aggregation specific components such as Lists is ofKeywordtype (v5 and above) or ofStringnot-analyzed type (v2).
Note
If a
$dataFieldis to be used both for searching and aggregating, it is recommended to create a.rawsub-field for a Text datatype field whose datatype is set as Keyword. And when aggregating (or sorting) is required, use$dataField.rawinstead of$dataField.Starting with
v5, Elasticsearch supports this as a default.



